Projects
These are projects that I have either completed for a class or on my own time. All projects were *Made on Earth by humans*.
Langchain Chains and Agents with MERN Stack Web Application (2025)
A full stack application using the MERN Stack with Typescript which implements both chain and agents using Langchain. The frontend react app uses Typescript and NextJS with TailwindCSS. The backend uses express with Typescript and mongoose to communicate with MongoDB. MongoDB was used to persist chat history. The agent is capable of remembering chat history without sending the entire history over the network to the LLM which in this case was Gemini. The agent was also capable of simple ReAct based reasoning with access to tools such as Wikipedia, a calculator, and a headless web browser. The application is fully dockerized with images for the frontend, backend, and nonrelational database. The application can be fully stood up using either docker-compose or kubernetes. This was further improved upon by using Kubernetes and a powershell script to deploy the application. here.
Masters Thesis (2020 - 2021)
Abstract: In this work, a conversational interaction was designed and implemented to test the effect of references to past events or shared experiences rephrased into motivational phrases within the context of working towards a diet related goal that can assist with type II diabetes over multiple sessions. Prior works that utilized a memory typically did not utilize a memory to refer to the past within conversations and when past events were referred to within a conversation, they were not utilized with motivational rephrasing. Most prior works did not analyze long term interaction or how references to past events should have been utilized. To further research in this area, the following research questions were posed:
- Does referring to previous sessions improve goal attainment?
- Does referring to previous sessions improve user experience?
- Does a variety of references differ from making the same reference?
- Provide clarity on how shared experiences should be used and not only whether they should be used.
- A motivational memory utilizing shared experiences with intrinsic motivational value
- Determine the effect of motivational references on goal achievement and user experience.
A link to the thesis report can be found here. A demo of some of the functionality can be found here. Code can be found here. Data collected during experiments are anonymized to follow GDPR regulations.
Teaching Tools (2012 - )
Genetic Algorithm (2015)
A project I worked on for Intro to AI at University of Michigan.
What I tried to do was create a python implementation of Roger Johansson's polygonal approximation program.
The program will receive an image as input. It will then try to approximate the image using a limited number of polygons. In the case of my implementation, I used 100 polygons instead of the 50 used in Roger Johansson's program. A genetic algorithm essentially immitates evolution. Each "generation" in the program represents a set of polygons with different colors, alpha values, and dimensions. This set is then filtered down to the top performing individuals within the generation. In this case, the top performing individuals represent the images that are most like the image provided as input. For every generation, I perform two operations that introduce diversity within the population. The first is the introduction of random mutations that will slightly modify the color, alpha values and dimension of individuals. The next operation is reproduction. I create the individuals who will form the next generation by taking half the traits from a high performing individual and taking half of the traits from another highly fit individual from the previous generation. This process continues for a certain number of generations (iterations). Eventually, the generated image will fall into a local maximum and stagnate at that maximum. Note: Gifs may disappear after completion on Chrome browser. If you wish to replay a gif, just reload your page.
| Ground Truth | Evolution Process (Animated Gif) | Final Image |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
User Styles (2016 - )
A collection of custom stylings for many different websites that can be used through an extension like Stylus or Stylish. Nothing groundbreaking. I just like having a darkmode for many of the websites I visit.
You can find the source code here
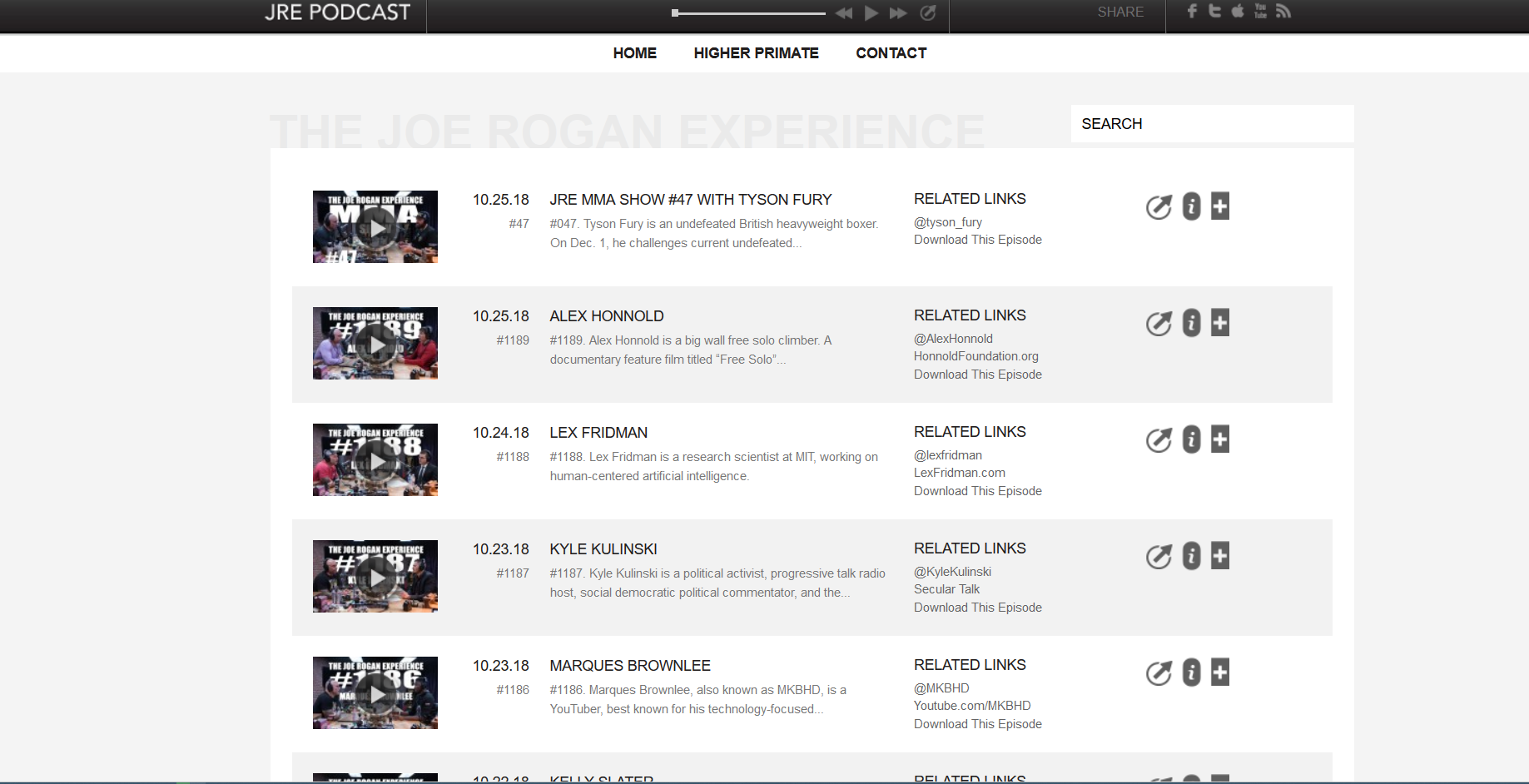
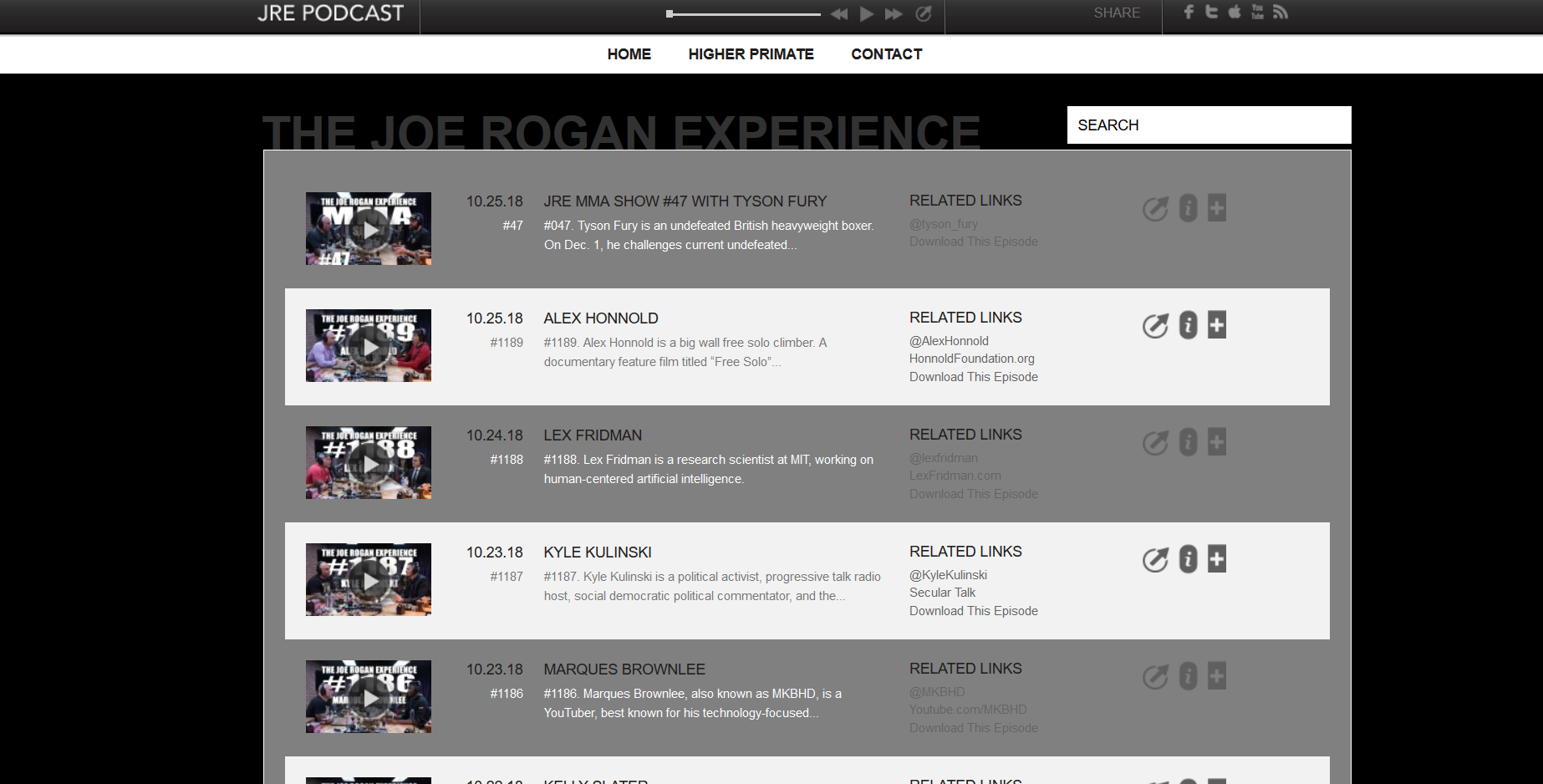
!This Website! (2018 - )
I've always wanted to create a personal website, so I decided to finally make one. This site will continuously be updated with new information. It is currently a static website with sass and javascript to add bells and whistles. Dependencies are brought in through Jekyll. This site has gone through a few major changes over the years. The move to use Jekyll has allowed for pages to be quickly expanded with content without the need for major updating of html. There has also been a move to a newer version of Bootstrap (v3 to v4) and a few artifacts of that migration may be left over. I intend to eventually make the underlying infrastructure more sophisticated, update the UI/UX strategy, compress and reduce file sizes for better load times, switch gifs to video for better load times, improve responsiveness or create a mobile version, add SEO, and maybe expand the scope of the project. This may take some time, however, because I don't intend to spend a single cent on the maintenance of this website.

MIT 6.S094 Deep Traffic (2018)
My most recent solution to the Deep Traffic deep reinforcement learning competition. More of a mini-project than an actual project. Details can be found here. It averages about 66mph. The car can travel at a max speed of 80mph.


Learning Arduino (2018 - 2019)
Projects and tutorials that I have completed with the Elegoo Uno Starter Kit. The intention was to use this to introduce myself to basic electronics and get a primer in sensors and simple robotics. Source code and examples can be found here.
Learning ProcessingJS (2019)
Powered through the ProcessingJS videos, challenges, and articles on Khan Academy so that I can eventually learn P5js and ml5js for machine learning applications and sophisticated visualizations. You can find the source code here. Khan Academy covers simple topics such as drawing, and works its way up to more complex topics such as games and natural simulations. All projects and challenges can also be viewed on my Khan Academy account.
Drawing and Animation




Games and Visualization


Natural Simulations



Learning ml5js (2019)
Projects and tutorials that implement and extend the functionality of different aspects of the ml5js library. Examples include image classification, pitch detection, video classification, and text generation. While it is useful, ml5js' existing models are not very accurate, and the library is very buggy because it is still a new library. Because of the limitations of the library in its current form, I intend to spend some time learning tensorflowjs after I learn Electron. Source code can be found here. Try it out for yourself: Image Classification, LSTM Text Prediction, Guitar Tuner.
Habit Tracker (2019 - ?)
A habit tracking electronjs app built using Angular 7. Still in progress. Source code can be found here. Progress is currently stalled, but it is a good example of many of the concepts used in Angular.
IN4010-12 Artificial Intelligence Techniques (2019 - 2020)
Artificial Intelligence related projects completed in the graduate level computer science course Artificial Intelligence Techniques at TU Delft. Source code is not public and was completed in groups. Projects include the following: calculation of posterior probabilities using Bayes Rule, automated bilateral negotiations through TU Delft's GENIUS framework, and reinforcement learning. Projects are coded in Python and Java.
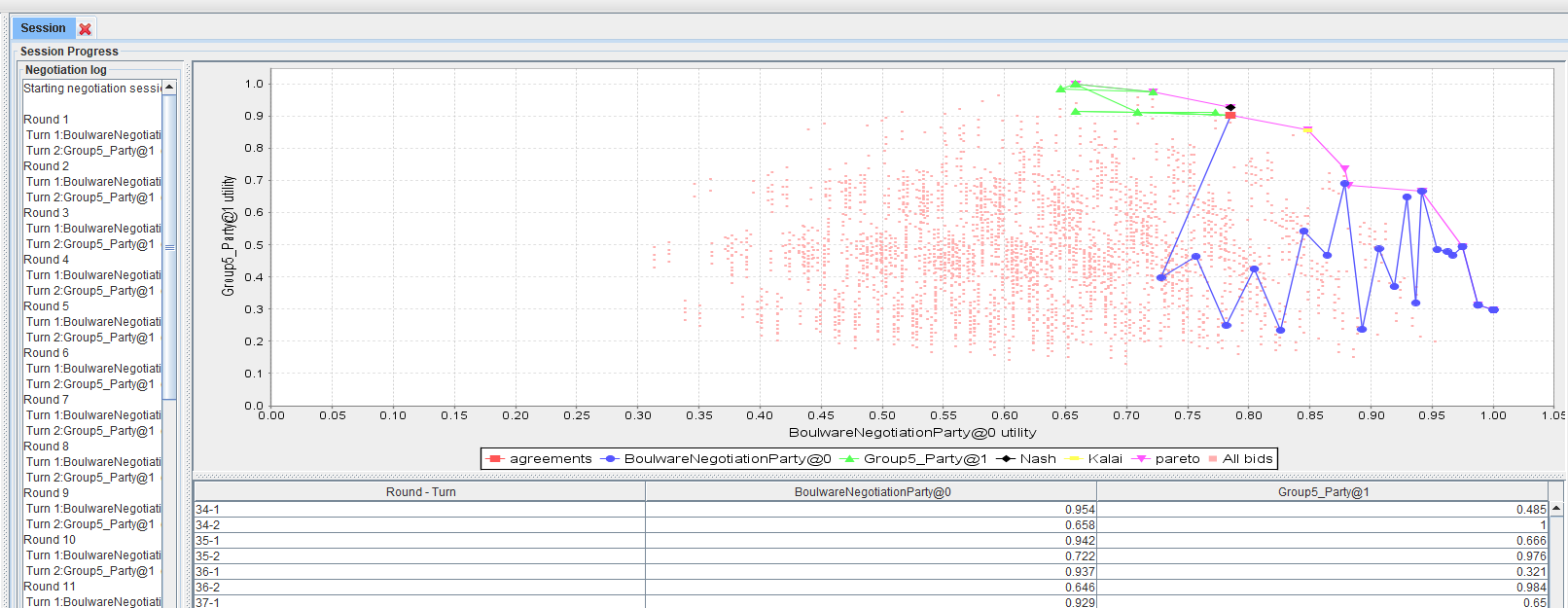
Automated Bilateral Negotiation
Reinforcement Learning and Deep Q Reinforcement Learning
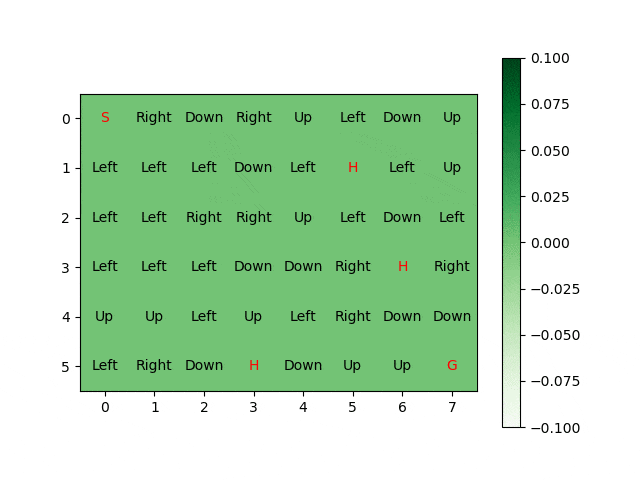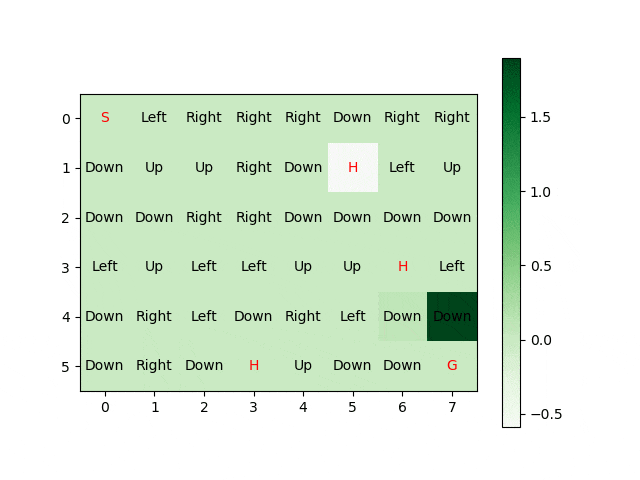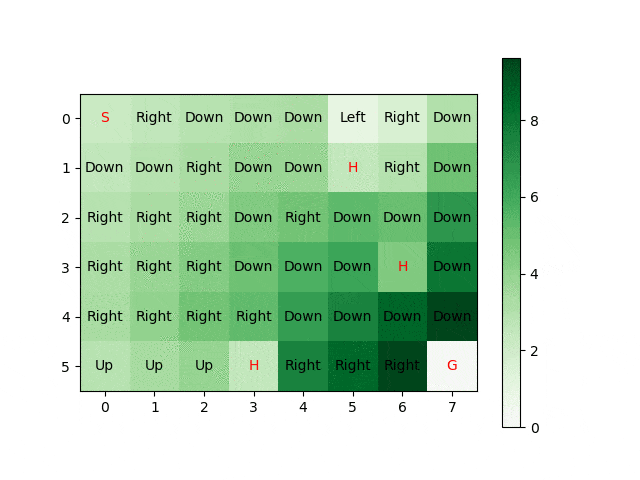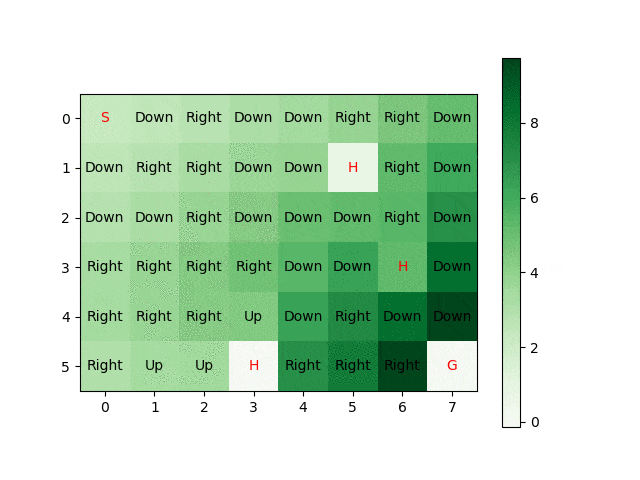

CS4070 Multivariate Data Analysis (2019 - 2020)
Data Analysis and machine learning related projects completed in the graduate level computer science course Multivariate Data Analysis at TU Delft. Source code is not public. Projects include the following: calculation of autocorrelation and maximum a posteriori for EKG scans to identify diseased and healthy patients, Kalman Filtering and Bayesian Linear Regression of data, and implementations of the Newton Raphson method, Metropolis Hastings Algorithm, Gibbs Samplers, and Gaussian Processes. Projects are coded in Matlab and Python.
Autocorrelation and Maximum A Posteriori estimation
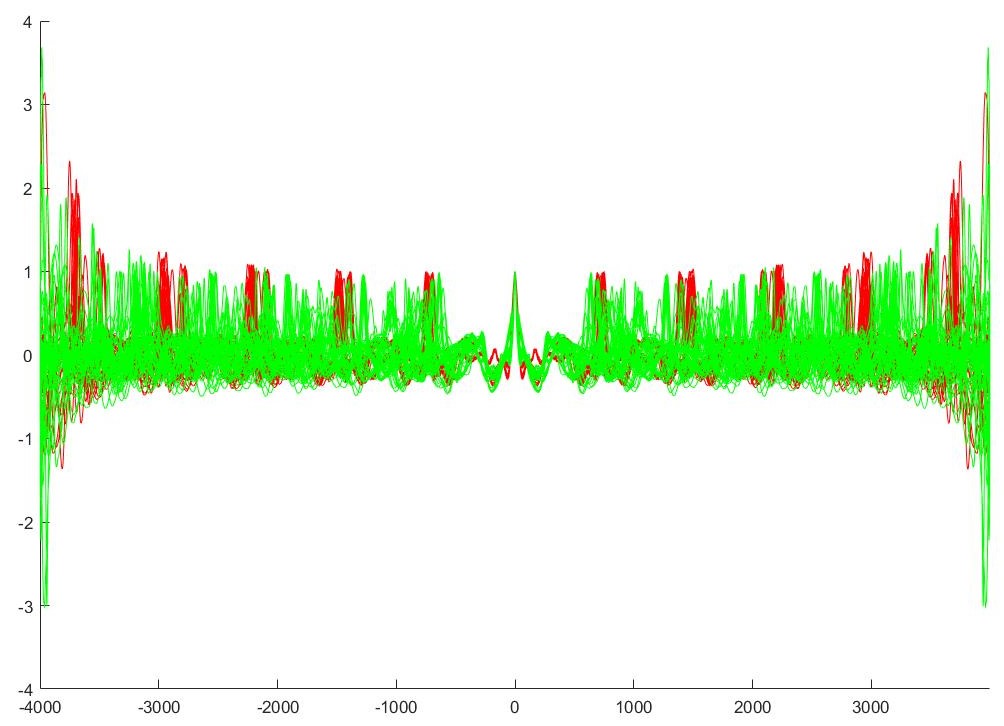
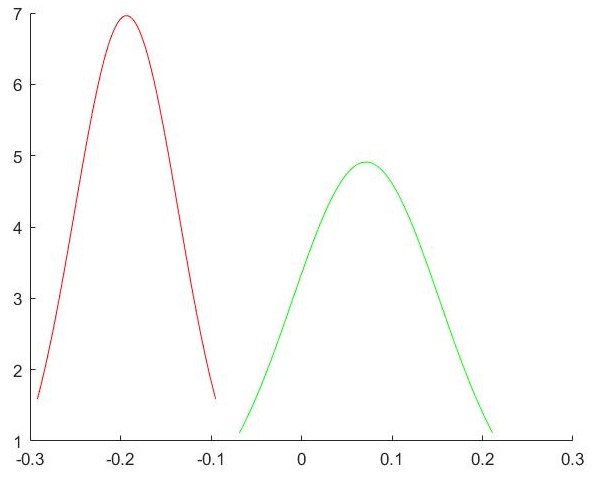
Bayesian updating for linear regression and Metropolis Hastings
Kernel Methods used in Gaussian Processes (Square Exponential, Polynomial, Neuronal)
IN4086-14 Data Visualization (2019 - 2020)
Data Visualization related projects completed in the graduate level computer science course Data Visualization at TU Delft. Source code is not public and completed in groups. Projects include the following: infovis projects through d3 and volumetric rendering/coloring/shading of 3d data. Projects are coded in Html, Javascript, Python and Java.
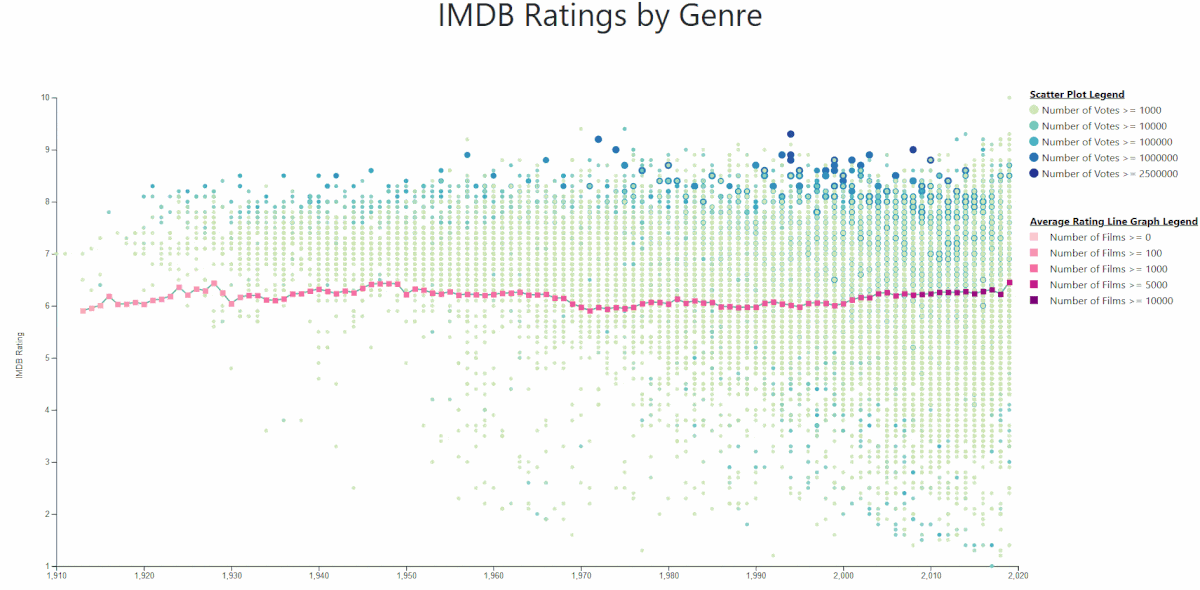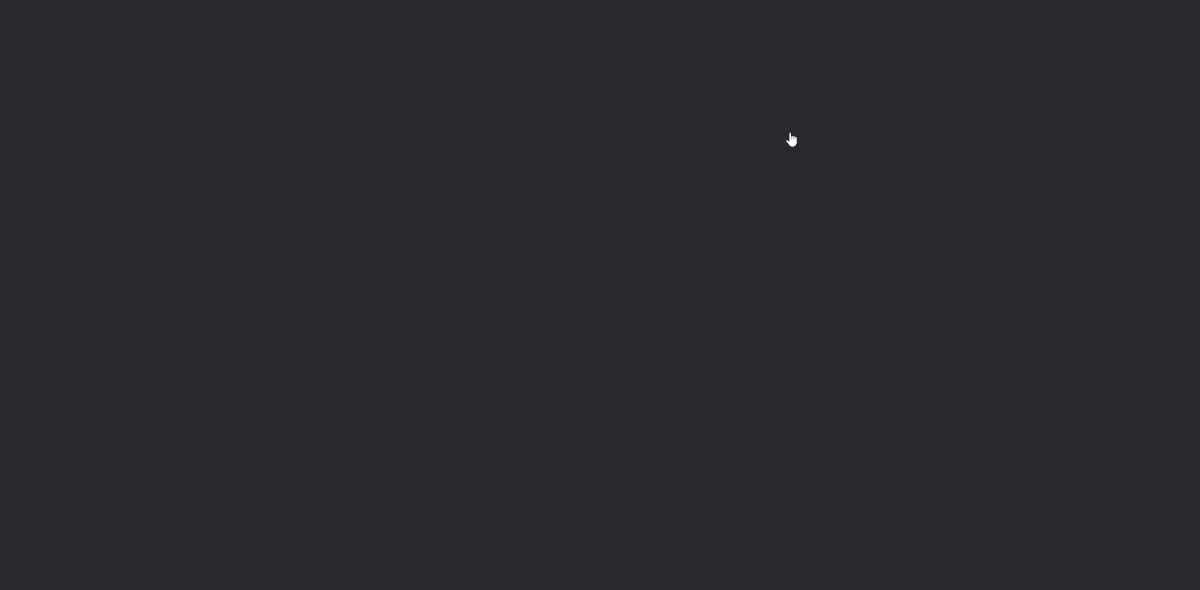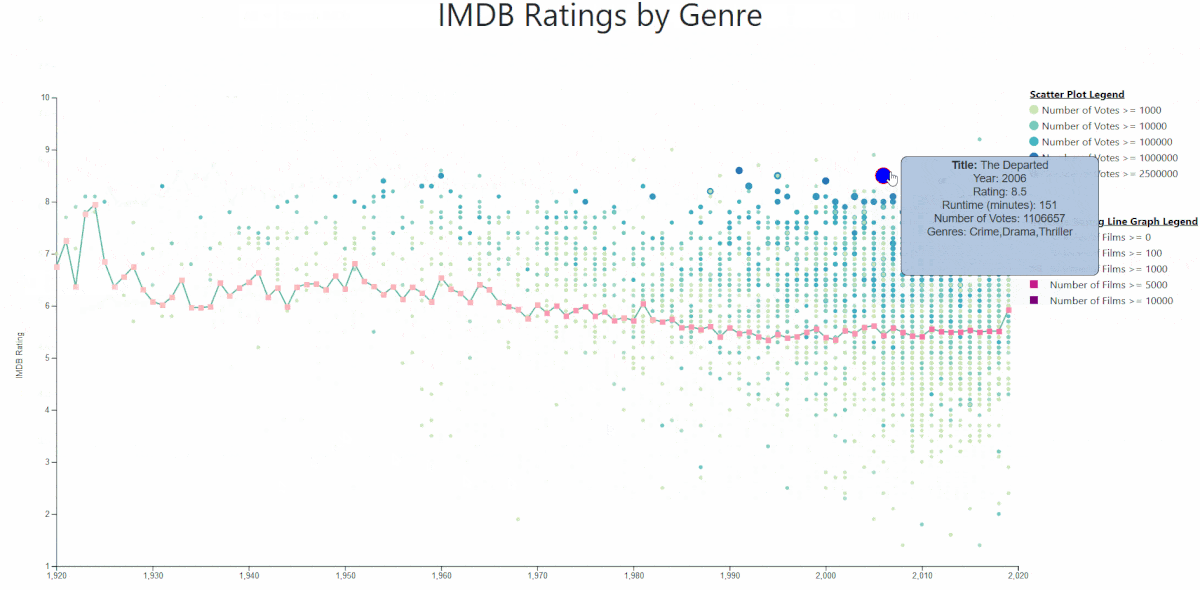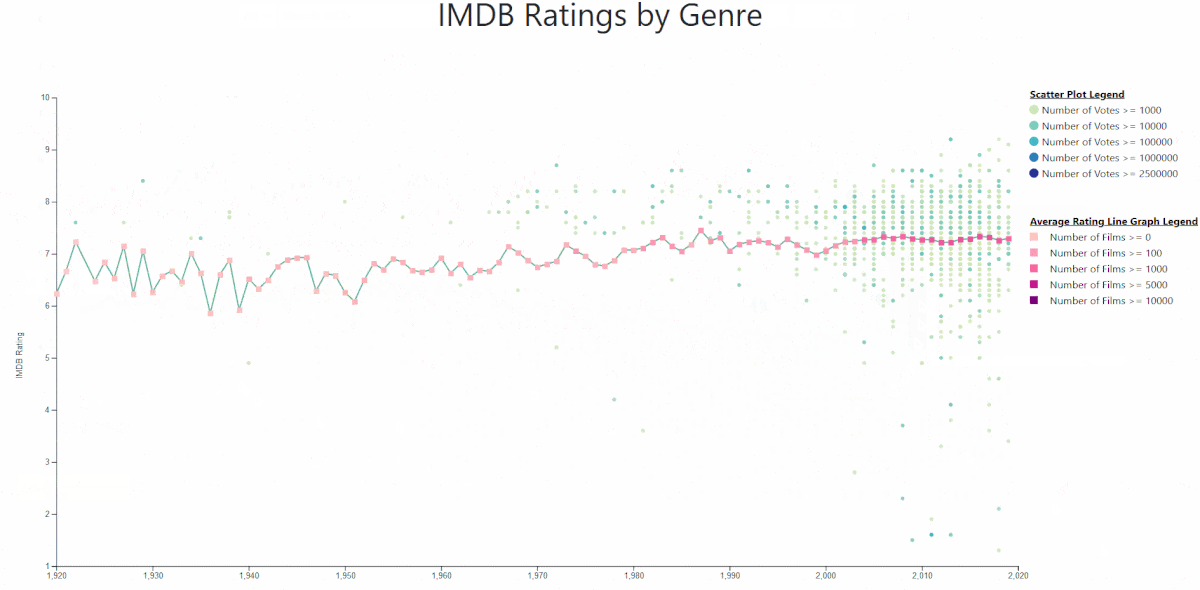
CS4220 Machine Learning 1 (2019 - 2020)
The Machine Learning 1 graduate level computer science course at TU Delft did not involve any projects, but had exercises that involved practicing concepts such as training data sets, and cross validation using different classifiers. This was done in python through the use of a pattern recognition library called Pr Tools. During the time this library was used in class, it was incomplete and buggy. Next steps would involve learning to use scikit-learn, tensorflow, and pytorch.
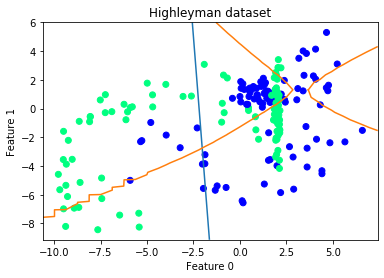
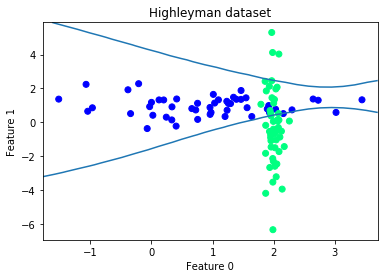
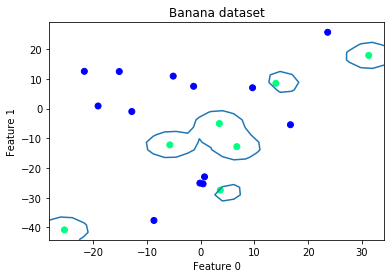
IN4325 Information Retrieval (2020)
Involved reproduction of two information retrieval papers in groups. The first paper related to sentiment judgements using natural language processing and machine learning with Spacy and scikit-learn. We compare the the performance of differrent classifiers as well as different feature representations such as bag of words and word2vec. Source code for the first project can be found here. The second paper is related to using semantic representations of Wikipedia table data for table lookup using SPARQL, bag of entities, word2vec, and then training using a random forest regressor. Source code for the second project can be found here.
CS4235 Socio-Cognitive Engineering (2020)
Designed an interaction with a robotic agent for the purpose of elder care, sensory stimulation, and cognitive exercise Designs were made through a collaborative process with other team members using Atlassian's Confluence. The interaction uses the Spotify api to play music. The robotic agent used was Softbank's Pepper robot. Interactions were programmed using an interaction tool that can be found here. A filmed version of a prototype of the interaction can be found here.
CS4240 Deep Learning (2020)
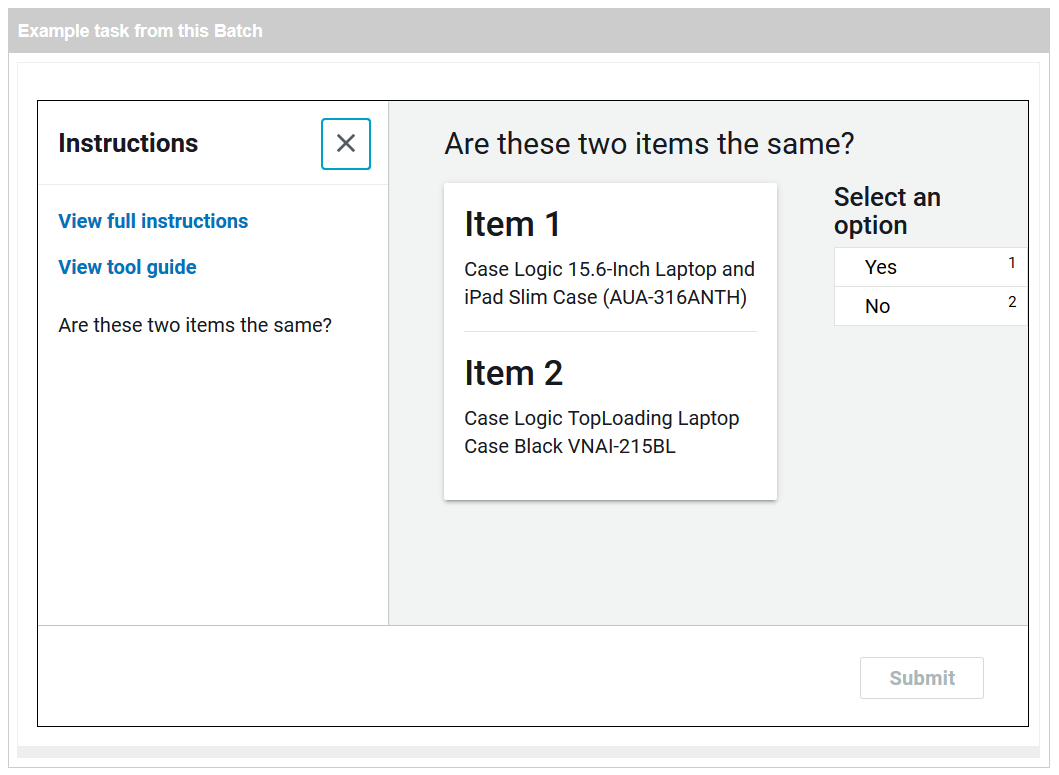
CS4145 Crowd Computing (2020)
Designed and implemented novel crowd sourcing tasks that can be used for the purpose of entity resolution. Crowd sourcing tasks were published and completed using Amazon Mechanical Turk. Data processing was performed using Python and Pandas. MTurk tasks were made using HTML. Code can be found here.
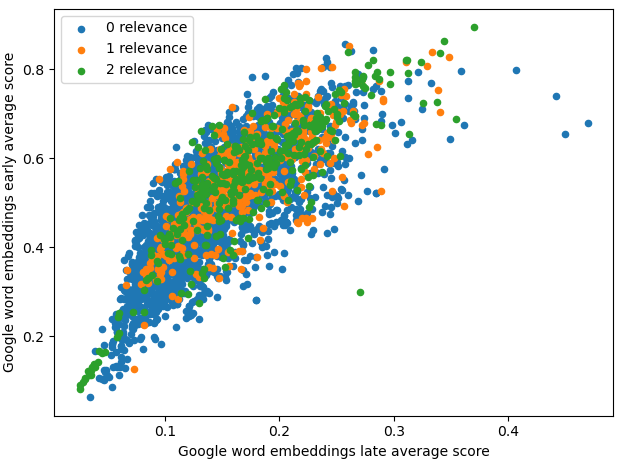
CS4065 Multimedia Search and Recommendation (2020)
Created a recommendation system for personalized game recommendations using Steam data. Recommendations were created using matrix factorization and more cutting edge methods. Multiple feature sets were used and features were fused using gaussian mixture models. These mixture models were used to generate relevance scores in an unsupervised fashion which were then used for neural collaborative filtering. Neural collaborative filtering uses Microsoft's reco utils library which leverages Tensorflow V1 for its implementation. A front end that displays different methods and the results of different feature sets were used for qualitative evaluation of recommendations. Steam data was processed using MYSQL. The recommendation system used Python and Jupyter. The front end used html, jquery, bootstrap v4, livereload, and D3.js. Code is not made available and is in a private repo maintained by TU Delft. A video describing the project can be found here.
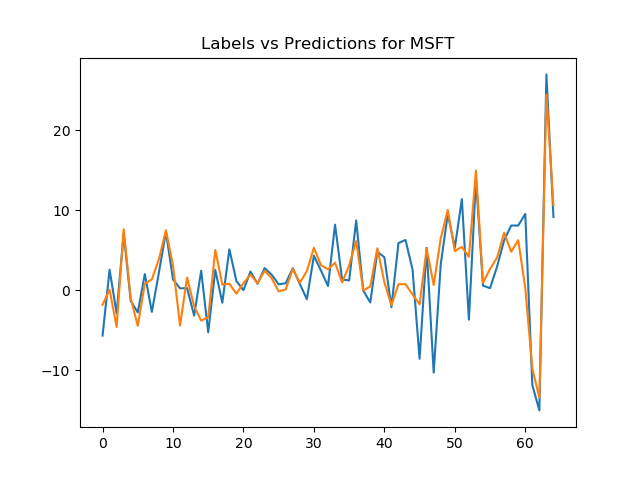
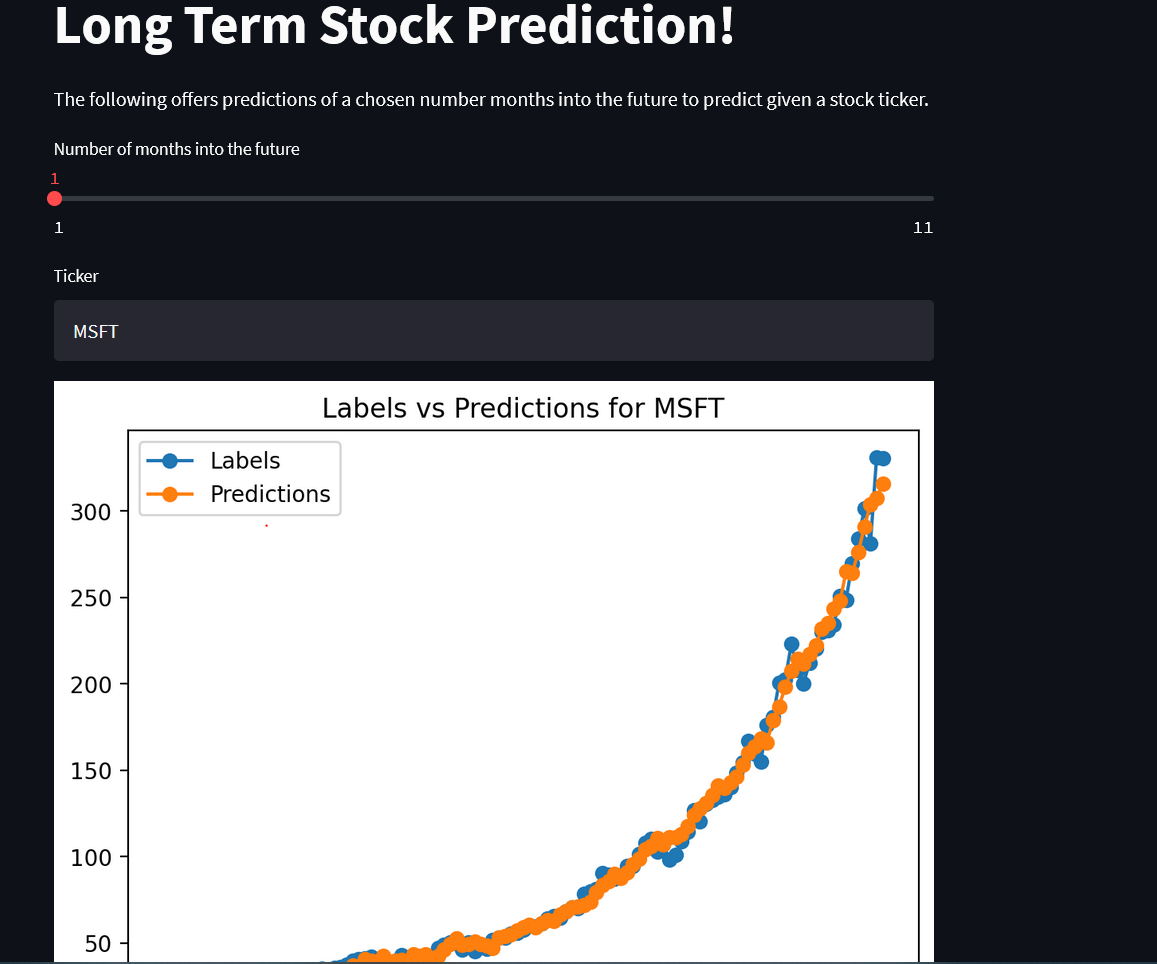
Basic Stock Prediction (2020 - )
Still in progress. Develop a full pipeline that can predict the value of a stock at a particular time in the future. Uses Sci-kit learn and the yFinance api. Unlike other approaches, this does not try to use linear regression based off of a future date, but rather based off of past data. Typical implementations try to plot a curve into the future while this tries to determine the value of a particular point using past data which can lead to greater flexibility and use for actual stock recommendations based on a particular timescale. Future plans involve using crossvalidation to reduce overfitting, including index data as features, ablation tests, and expanding to a larger set of tickers. Source code is public for now and can be found here. I believe use of this project as well as development of other algorithms for modeling stock behavior in my personal investment strategy makes me a self employed amateur quantitative trader now instead of just a retail trader. In 2021, I made the project available for use through streamlit. Those who wish to try the project can be given access upon request depending on what you intend to use the project for. If you wish to use the project to profit, let me know and we can negotiate the price of access.
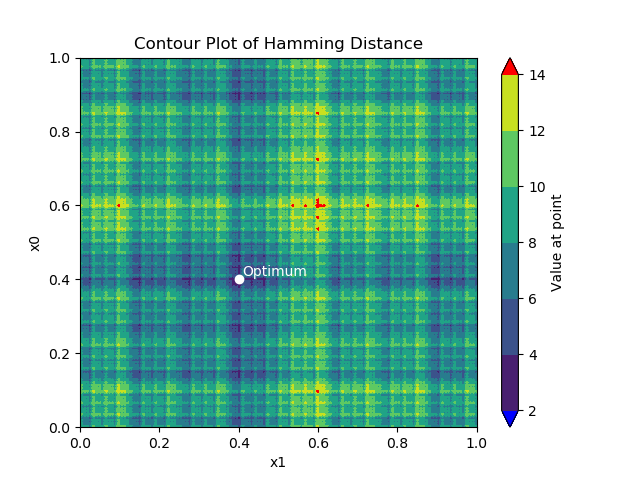
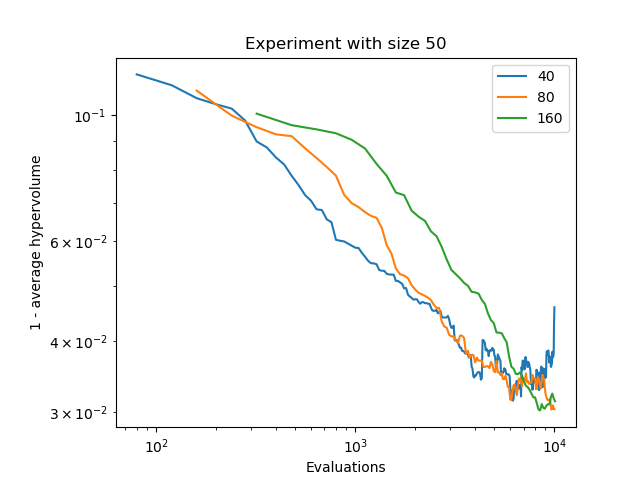
CS4205 Evolutionary Algorithms (2020)
Used and implemented different evolutionary algorithms. Completed different analyses such as scalability to determine the usefulness of certain algorithms for certain optimization problems. Algorithms covered include simple genetic algorithm with multiple types of crossover in Python using DEAP as well as in Java, estimation of distribution algorithm, gene pool optimal mixing evolutionary algorithm, binaryGomea, AMaLGaM with univariate and full implementations, NSGA-II, and evolutionary programming that uses sci-kit learn to generate a function. Problems solved include the maxcut problem, weighted max cut problem, sphere problem, rotated ellipoid problem, and multiobjective optimization problems. Implementations were made using Python, Java, and C. Source code has not been made public.
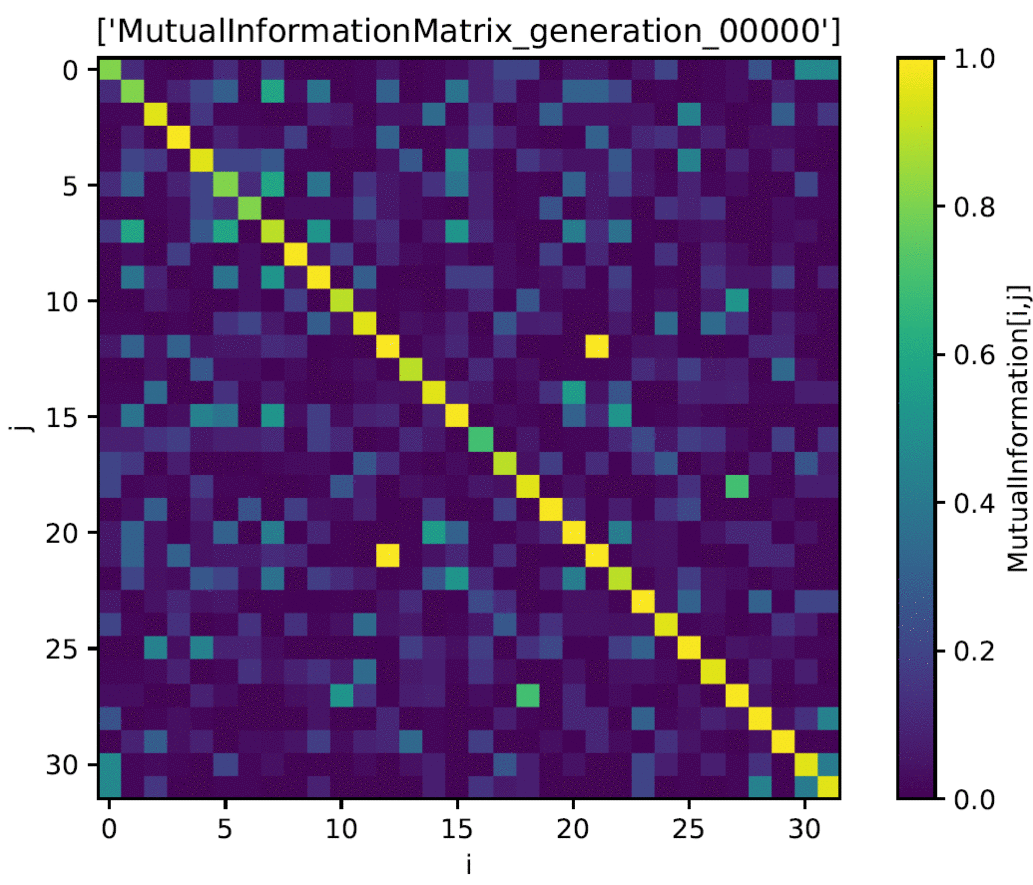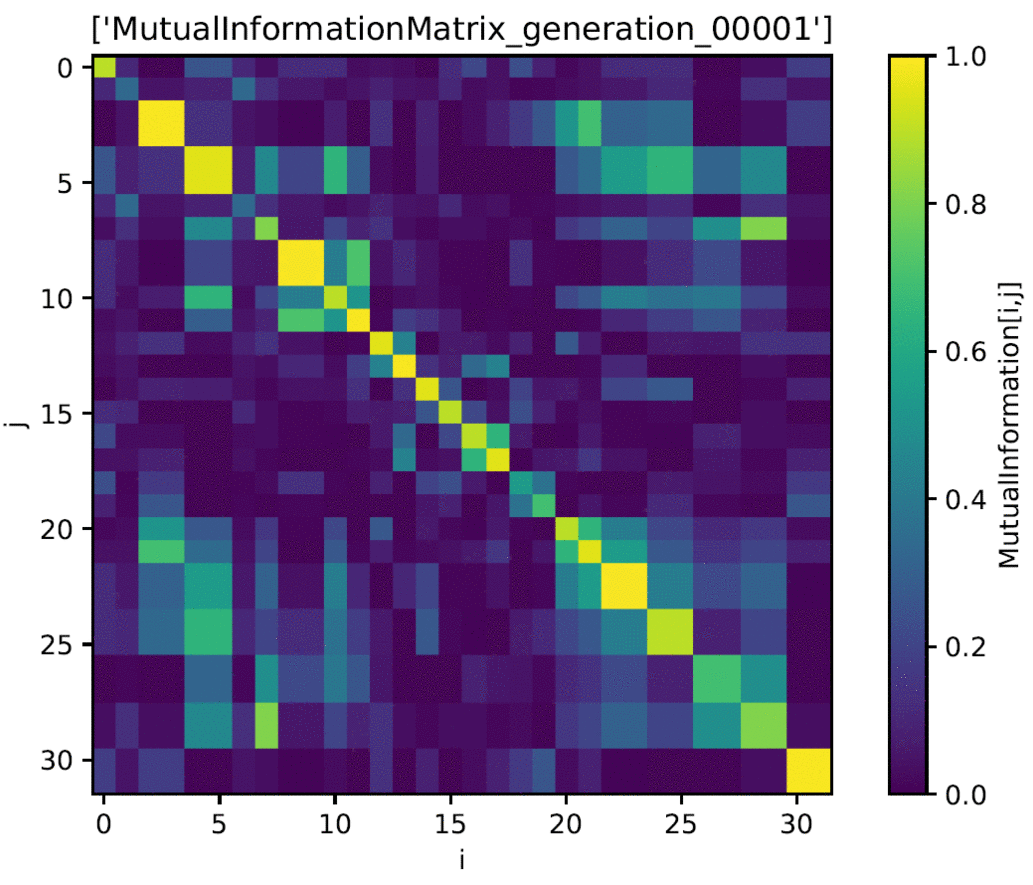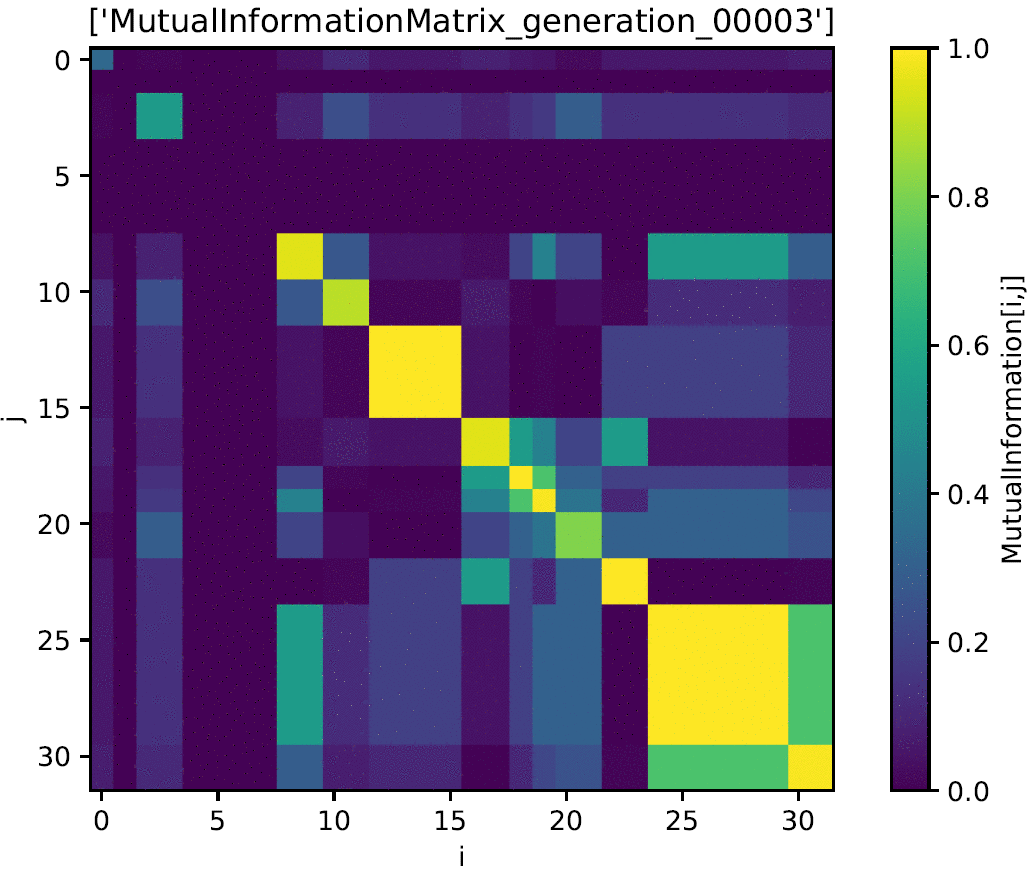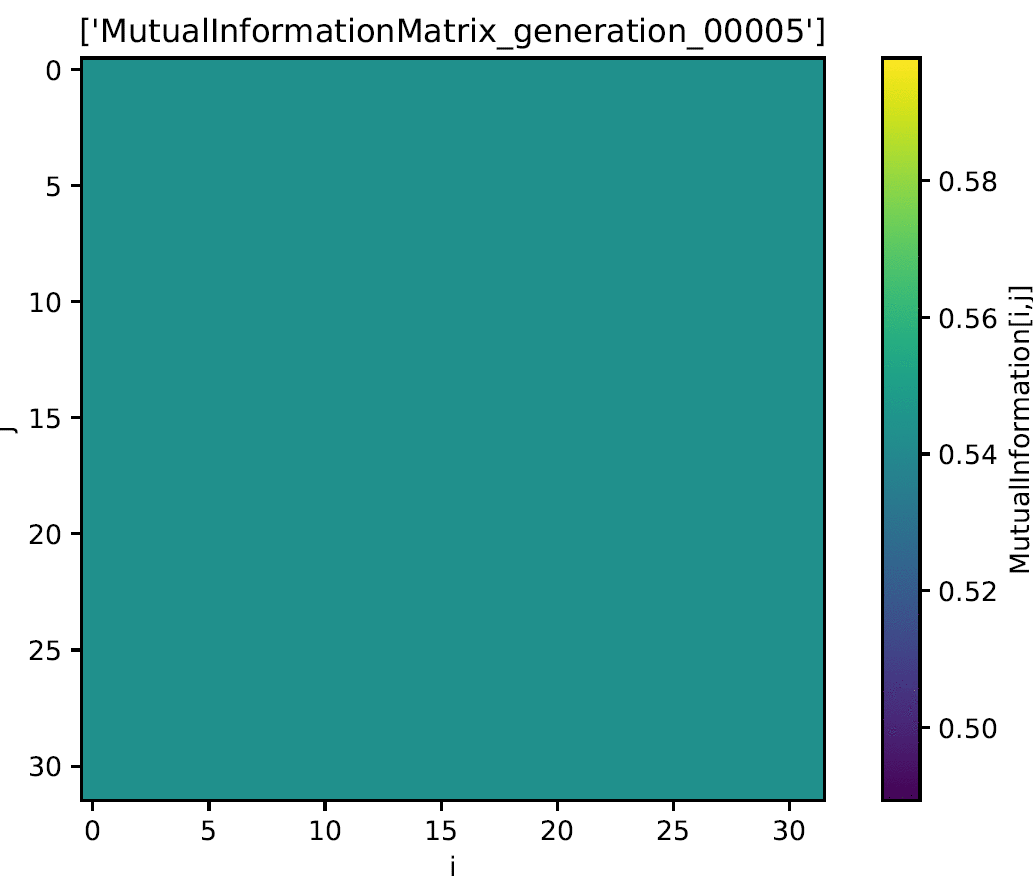
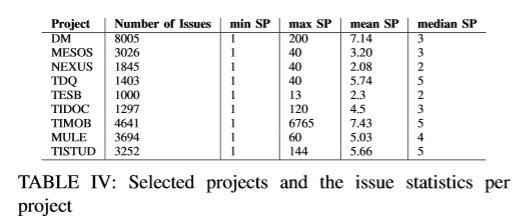
IN4334 Machine Learning for Software Engineering (2020)
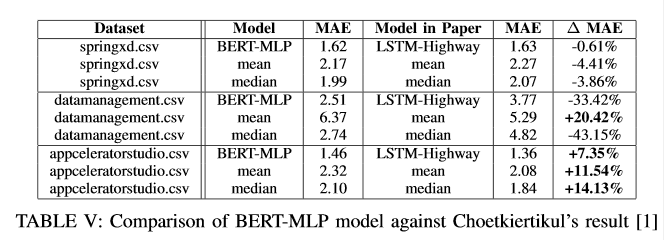
Used cutting edge techniques to apply deep learning towards the problem of story point estimation. In a group, we applied BERT (Bidirectional Encoder Representations from Transformers) on data that was extracted from public Jira servers such as Apache and Mulesoft. Our approach was compared to that of Choetkiertikul et al.'s paper which utilized a recurrent highway network. Our approach introduces some novel additions such as the use of BERT and team dynamics which was utilized in the form of a sliding window. While our results were not an improvement over the results of Choertkiertikul et al., the project unveiled some inconsistencies within the work of the original paper as well as brought some of the shortcomings of Agile methodology and story point estimation to light. The project was coded in Python with the Jira API library used for gathering data from Jira and Pytorch used for implementing models. Models were run using Google Collab which allowed for the use of higher performance GPU's. Code is not made publicly available and the data is not made publicly available due to concerns about developer privacy.
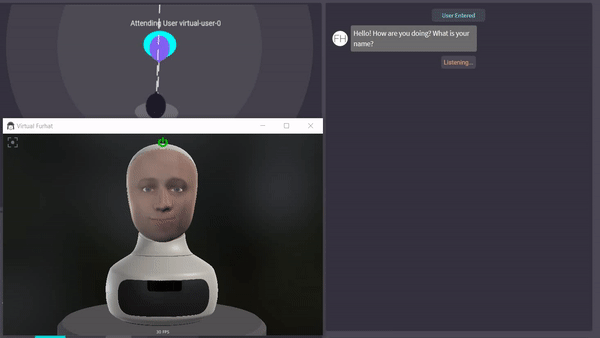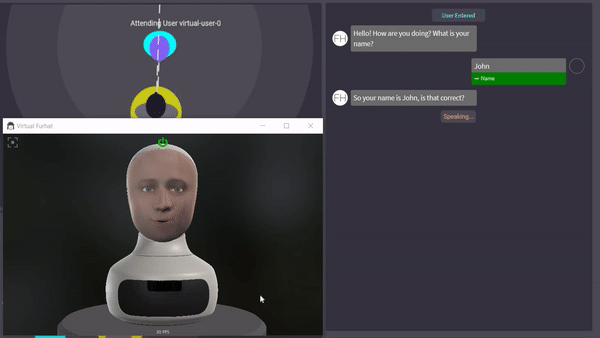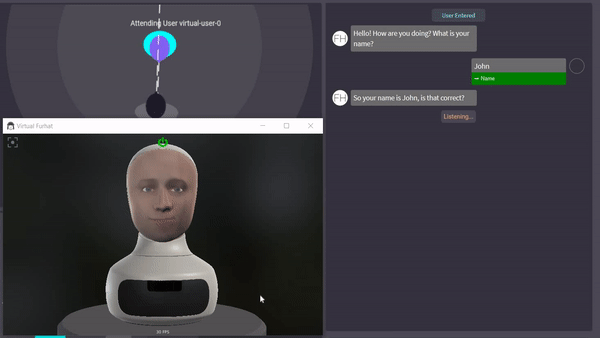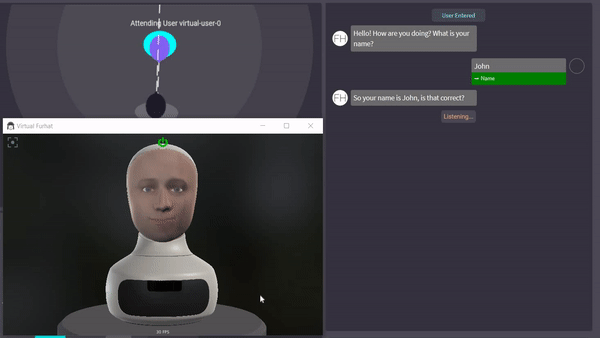
CS4270 Conversational Agents (2020)
Worked in a group to create an interaction that was capable of teaching the basic math concept of division using the Furhat robot. Work involved affect detection to determine the frustration level of students, gestures, simplistic gaze, and the dialogue. Code has been made public and may be used in part for the next year's Conversational Agents course. Code can be found here. Affect detection has been implemented using the Aff-Wild models which utilizes Tensorflow.
Deep Learning Based Video Upscaling (2020)
Upscaling of video using neural nets. Neural nets are trained using images that are downscaled. I didn't bother to put this on github since there are literally many tutorials that show how to use convolutional neural networks. The point of this project was to see what was possible using basic techniques rather than to innovate on existing architectures. CNN's are run on individual frames which are then collected and played at the frame rate of the original video. In my case, I used a tried and tested pretrained network in addition to additional training to avoid the pains of training for hours or days on end.
The videos shown here are not the best quality due to compression used to reduce file size for better load times on the web, but it can be seen that lines are sharper and pixelation is minimized. In cases where images are highly degraded, the neural net adds information to the image to make it seem more convincing after upscaling.
Pytorch Refresher (2021 - )
I have not trained neural nets from scratch for more than a year now, and since the field moves fairly quickly, I wanted to have some resources I could use to refresh my memory and fill in some gaps. This repository contains a collection of scripts that cover different concepts which were constructed from publically available Pytorch tutorials and snippets which were then modified to be used for other problems for the sake of practice. The repo currently contains the following: Deep Q Learning example for OpenAI's CartPole, Deep Q Learning example for OpenAI's Acrobot, Deep Q Learning example for Mario (which may not work and requires a large amount of training time), standard feed forward neural networks applied to MNIST, KMNIST, and QMNIST datasets, a CNN example for the CIFAR10 dataset, an RNN for name generation, an FGSM tutorial from Pytorch, a simple feedforward network that takes in integers from a list and outputs an integer to illustrate datasets and loaders, and finally an RNN applied to the problem of last name classification based on country of origin. The repository can be found here. I recommend running these in a Google Collab notebook with a higher number of epochs if you don't want wait and twiddle your thumbs by running the code locally only to get subpar results. Feel free to take this code and make modifications to see how playing around with the hyperparameters and architecture can yeild different results.
Learning Tableau (2022 - )
Excel is too simplistic, and d3 can be a pain to work with at times, so I started taking a look at Tableau for data visualization. This is a repository containing dashboards and sheets that have been made with publically available datasets. All visualizations were made using Tableau Public 2022.1. The repository can be found here.
Conway's Game of Life (2023)
An implementation of Conway's Game of Life written in simple html, javascript and css. Since Lex Fridman kept mentioning it and cellular automata in general, I was curious how it worked. Can be run within a browser. Try it out for yourself: Conway's Game of Life
Dreaming of a Hopeful Death (2023)
For the better part of a few months, I have spent time generating images using Dall-E 2 and programming dialogue for my adaptation of my novel of the same name. This project was written in python and uses the Ren'Py engine. Code can be found publically available here.
Text to Video Generation (2024)
Utilized ModelScope Text-to-Video to generate a video based on a text prompt. This was the first part of a collab pipeline which then used Video2x to upscale, denoise, and add detail to the original video since the original videos generated were of low resolution. This was done using Google collab and a desktop GUI, but but it is also possible to run ModelScope on hugging face. As a side effect of upscaling, some of the more grainy noise which created the impression of detail were inadvertently removed. Furthermore, there are a number of artifacts which can be seen in the video and either originate from ModelScope, or from Video2x. It should also be noted that there is the presence of a Shutterstock watermark which is present due to the training data used on the pretrained model. No further tuning was done for ModelScope except for some experimentation with hyperparameters to see how output could be improved or would differ.
Nextjs Frontend with Routing and APIs (2025)
A frontend with routing and APIs written in Nextjs and Typescript. This was made as a learning exercise by following Vercel's Next.js tutorial and can be found here. Vercel was used for hosting with the database being neon postgres.
CS4165 Social Signal Processing (2020 - 2021)
Applied machine learning techniques and statistics to analyze and annotate behavior within social contexts as a group. The problem focused on in this project is that of the relationship between prosody and memory. Specifically, we analyze how those interacting with a conversational agent or speaker entrain their prosody to a tutor's speech over time based on whether the participant of the experiment is interacting with a tutor with a human face or a robot face. To do this, we showed participants of the experiment videos of a human tutor and of a robotic tutor with the same audio as the human and the human's facial gestures mapped to the robot so the robot matches the movements as well. The robot used was the Furhat robot. We used recorded audio to analyze levels of entrainment, and we used a questionnaire to analyze levels of recall and recognition. Scripts were made in Python with Furhat using Kotlin. For analysis of audio, we looked at certain features such as f0, mean and max values of pitch, HNR, and different values of shimmer and jitter. To do this, we utilized the Pydub and Parselmouth libraries in python. We then calculated convergence, proximity, and synchrony to relate the features to acoustic-prosodic entrainment. To measure statistical significance, we used t-tests and mann-whitney u tests after using z-scores for standardization. Code can be found here. The work from this course is has lead to a publication in the form of a research article within the 2nd ACM Multimedia Workshop on Multimodal Conversational AI which was part of ACM's 2021 Multimedia conference.